Analyse en Composantes Principales — Dataset Decathlon (R)
Objectif
Comprendre la structure des performances des athlètes du décathlon et identifier les dimensions principales expliquant la variabilité des résultats. L'enjeu : au-delà des scores bruts, qu'est-ce qui structure réellement la performance décathlonienne?
Méthodologie
Analyse en composantes principales réalisée sur variables centrées-réduites à l'aide du package FactoMineR. L'interprétation repose sur les valeurs propres, les contributions, les cos² et le cercle des corrélations.
Résultats clés
- Les deux premières composantes expliquent environ 55% de la variance totale
- Opposition marquée entre épreuves de vitesse/explosivité et épreuves techniques
- Forte structuration des disciplines autour de groupes cohérents (sprint, sauts, lancers, endurance)
Visualisations
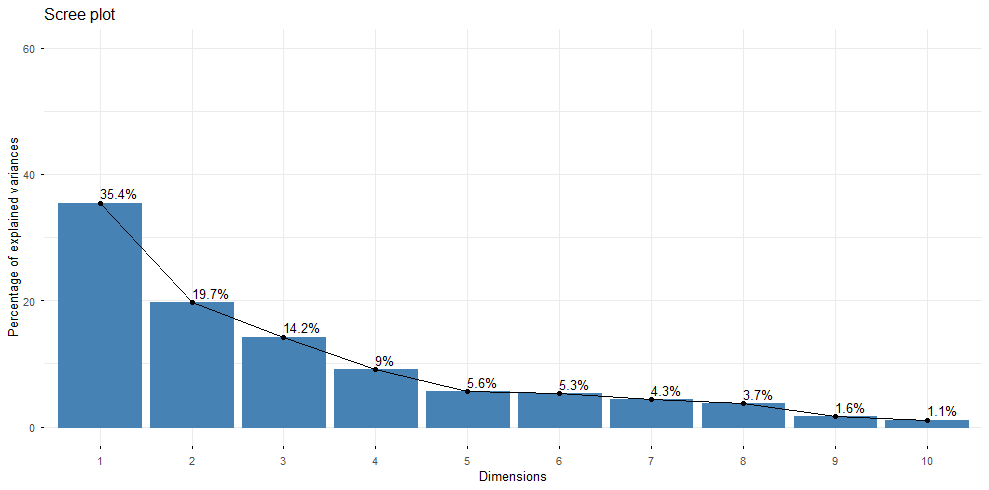
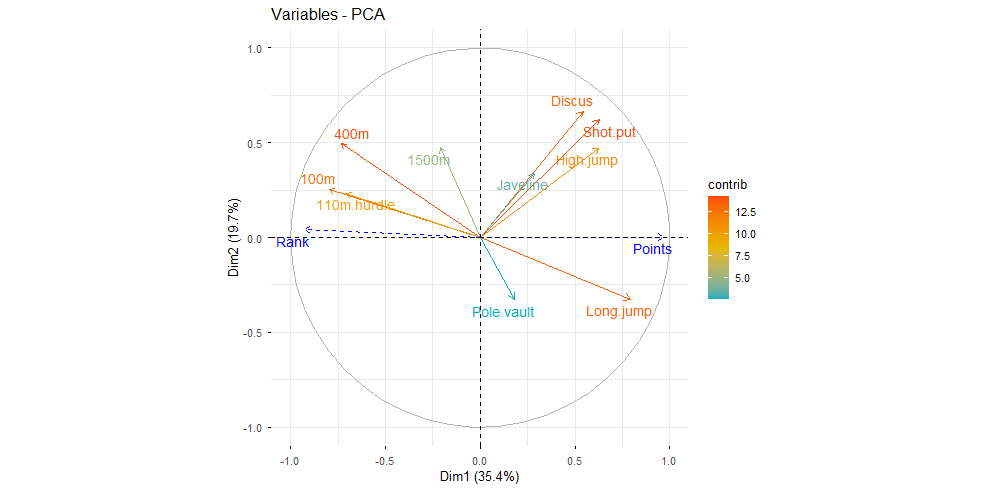
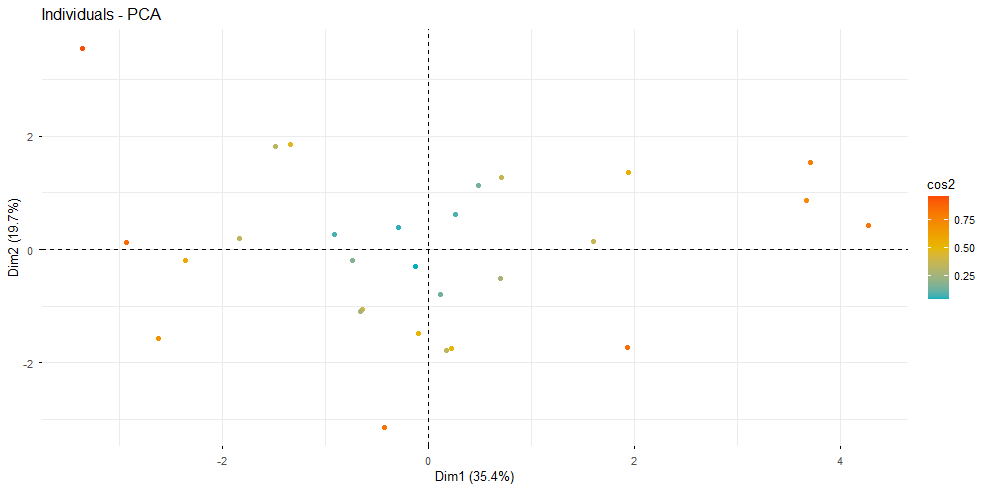
Conclusion analytique
L'ACP met en évidence une organisation claire des profils athlétiques. La performance globale ne repose pas sur une dimension unique, mais sur des compromis entre vitesse, puissance et endurance. Certains athlètes excellent dans les épreuves explosives tandis que d'autres dominent les épreuves d'endurance.
Clustering Non Supervisé — Identification de types de mines
Objectif
Explorer la capacité de méthodes de clustering non supervisé à identifier des types de mines à partir de variables physiques et géométriques. Question centrale : existe-t-il une structure naturelle dans ces données, ou les classes sont-elles largement arbitraires?
Approche
Le projet débute par l'application de K-means comme méthode de référence, suivie d'une analyse critique de ses limites. Plusieurs méthodes avancées ont ensuite été testées : clustering hiérarchique, DBSCAN, Gaussian Mixture Models, ainsi que des approches hybrides (ACP, Mahalanobis, autoencodeur).
Résultats
- Faible alignement entre clusters détectés et classes réelles (ARI bas)
- Sensibilité marquée aux variables discrètes et à la normalisation
- GMM offrant une segmentation visuellement plus cohérente que K-means classique
- Pas de critère unique convergeant vers une solution claire
Visualisations
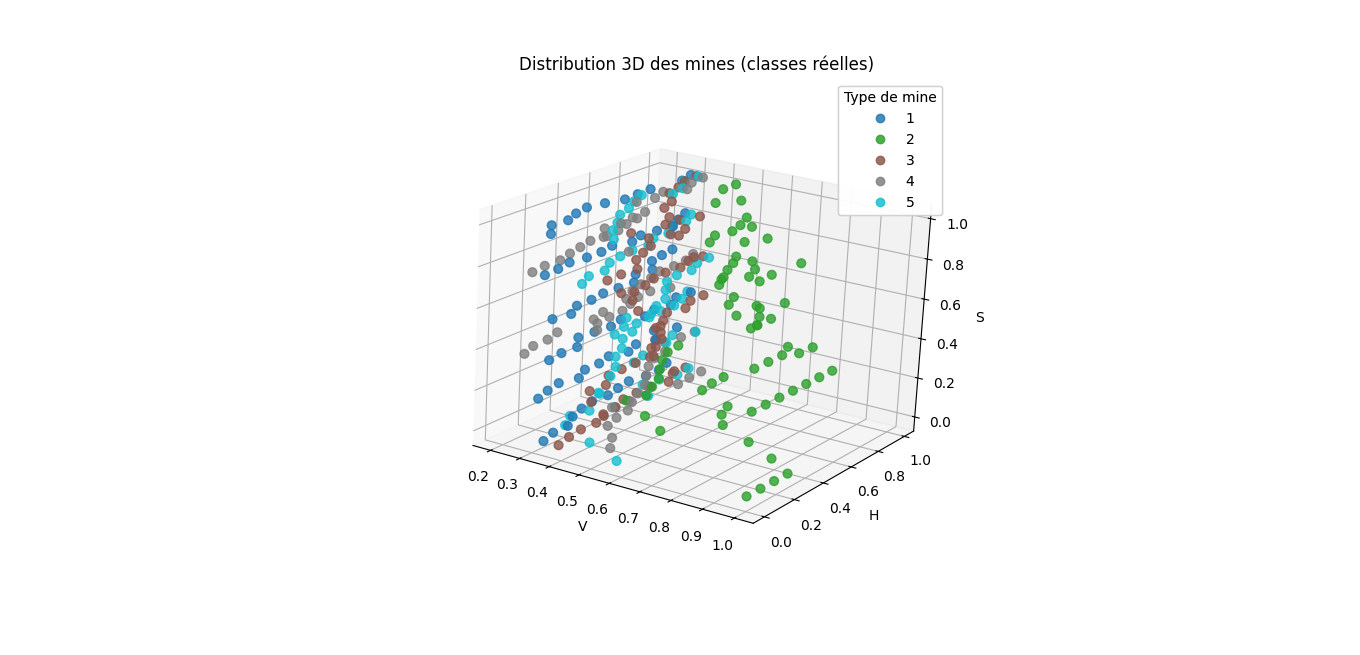
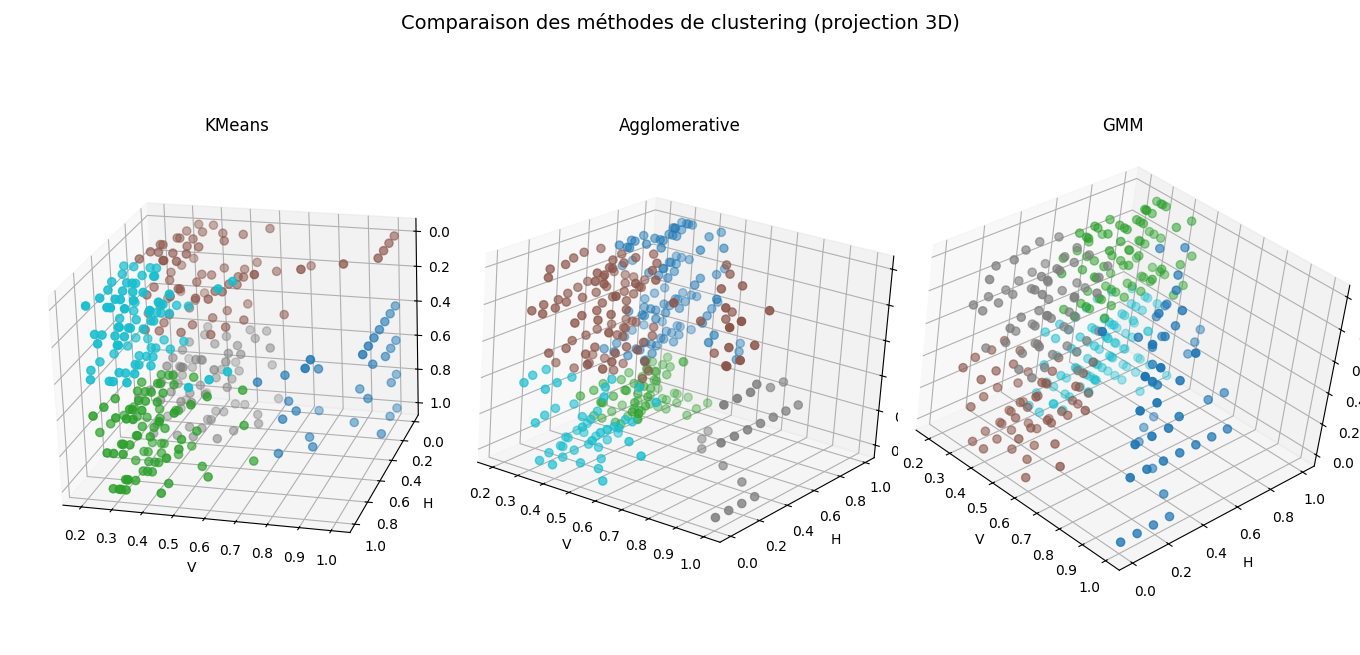
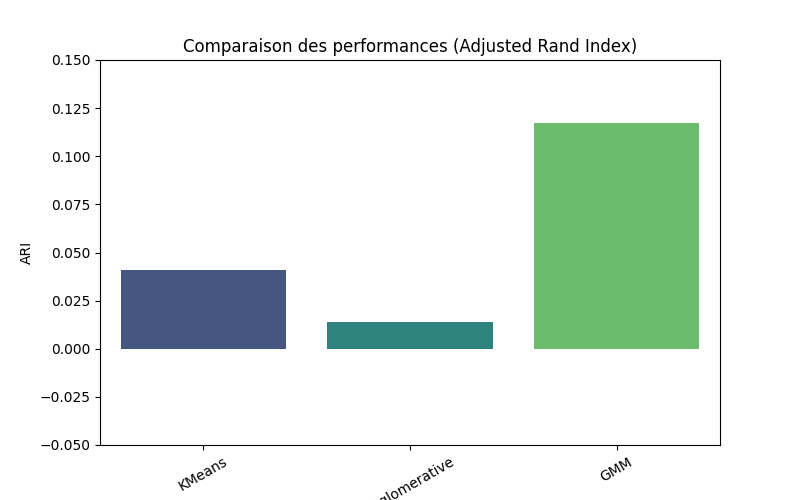
Conclusion analytique
L'absence de séparation nette suggère que les types de mines ne sont pas entièrement définis par les variables observées. Ce résultat, apparemment négatif, est informatif : il indique que des variables supplémentaires ou des informations contextuelles seraient nécessaires. Ce projet illustre pourquoi l'échec d'un algorithme non supervisé peut justifier une approche supervisée.
Analyse de Séries Temporelles — Ventes mensuelles (Excel)
Objectif
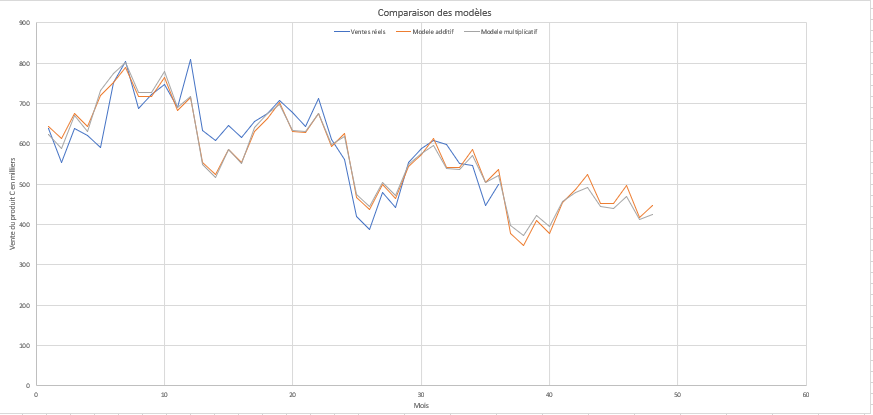
Analyser l'évolution des ventes mensuelles d'un produit sur 3 ans (36 mois) et déterminer si une décomposition additive ou multiplicative explique le mieux la dynamique des données.
Méthodologie
Calcul de moyennes mobiles centrées pour isoler la tendance long terme. Extraction de la composante saisonnière via deux approches : modèle additif (Yt = Lt + St + Rt) et modèle multiplicatif (Yt = Lt × St × Rt). Ajustement linéaire de la tendance lissée. Comparaison des résidus pour identifier le modèle optimal.
Résultats clés
- Données: 36 mois de ventes (min: 447k, max: 808k, moyenne: 614k unités)
- Tendance déclinante sur la période avec baisse de 637k (début) à 499k (fin)
- Saisonnalité multiplicative significative: pics d'été (coefficients > 1.14) et creux d'hiver (< 0.92)
- Le modèle multiplicatif offre un meilleur ajustement avec résidus légèrement plus stables que l'approche additive
Visualisations
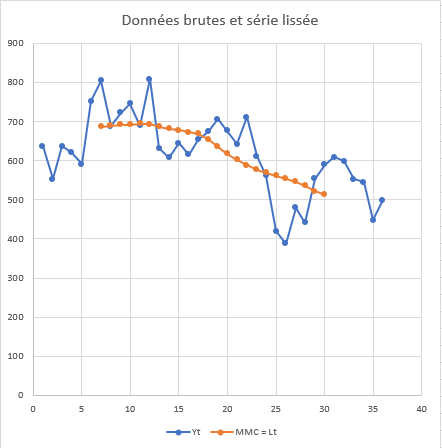
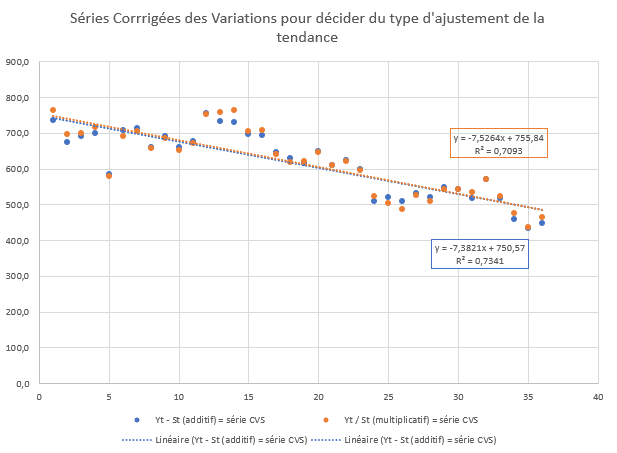
Conclusion analytique
Cette analyse démontre que le choix du modèle de décomposition affecte directement la qualité de la prédiction. Les ventes montrent une tendance baissière avec une saisonnalité multiplicative marquée : les variations saisonnières s'amplifient ou se réduisent proportionnellement au niveau moyen des ventes. Ce pattern est typique des produits saisonniers où les écarts absolus augmentent ou diminuent avec la tendance générale. Une bonne modélisation permet une prévention de demand plus fiable pour la planification.
Conception de Base de Données — Réseau RATP (SQL)
Objectif
Concevoir et manipuler une base de données relationnelle simulant un réseau de transport urbain (RATP). L'enjeu : modéliser correctement les relations complexes entre stations, lignes, correspondances et trajets utilisateurs.
Compétences
Traiter, analyser, valoriser — conception logique, modèle relationnel, requêtes SQL avancées.
Approche
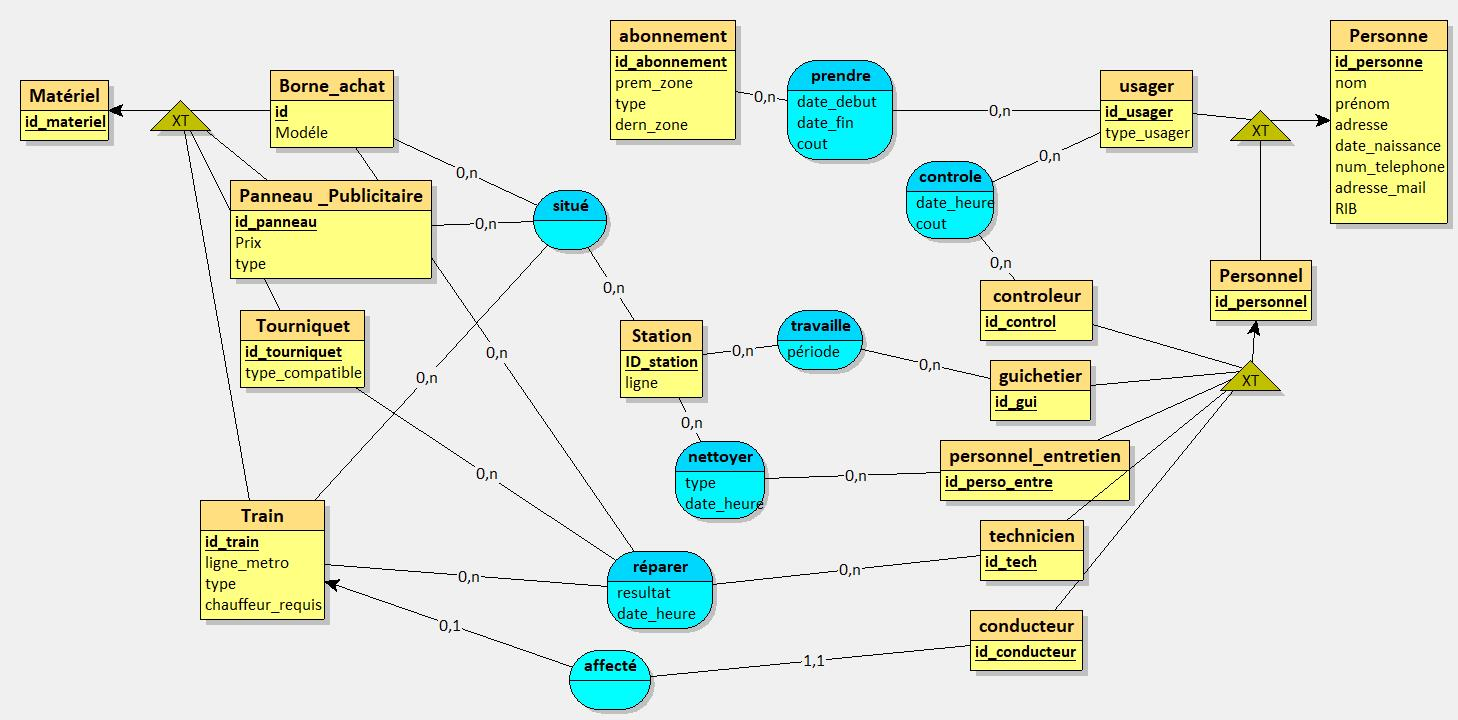
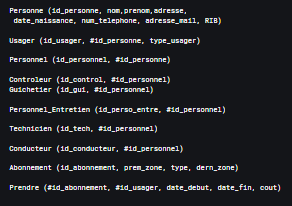
À partir d'un test visant à comprendre le fonctionnement du réseau RATP, nous avons analysé les données disponibles pour modéliser les entités et leurs relations dans un Modèle Conceptuel de Données (MCD). Ce MCD a ensuite été transformé en Modèle Logique de Données (MLD) pour créer une base relationnelle solide.
Travail réalisé
- Conception d'un schéma relationnel (stations, lignes, arrêts, trajets)
- Requêtes SQL complexes : jointures multi-tables, agrégations, sous-requêtes
- Requêtes analytiques : trajets les plus fréquentés, correspondances, temps de trajet
- Modélisation des entités et relations (MCD → MLD)
- Respect des contraintes d'intégrité (clés primaires, clés étrangères)
Visualisations
Conclusion analytique
Ce projet montre l'importance d'une bonne modélisation de données dès le départ. Une structure mal pensée crée des anomalies et complique les requêtes. Une base bien conçue permet des analyses rapides et fiables, même sur de grands volumes. Une bonne base de données est le fondement de tout projet data solide.
Data Visualisation & Décisionnel — Tableaux de bord Power BI (SNCF)
Objectif
Concevoir des tableaux de bord interactifs à partir de données SNCF afin de suivre des indicateurs clés et faciliter l'aide à la décision. L'enjeu : transformer des données brutes en insights actionnables pour les décideurs.
Travail réalisé
- Nettoyage et structuration des données (20k+ enregistrements, gestion des valeurs manquantes)
- Définition de KPI pertinents (trafic, chiffre d'affaires, répartition des trajets, taux de remplissage)
- Création de dashboards interactifs avec filtres dynamiques et drill-down capabilities
- Optimisation des visualisations pour une lecture rapide et des décisions informées
Dashboards
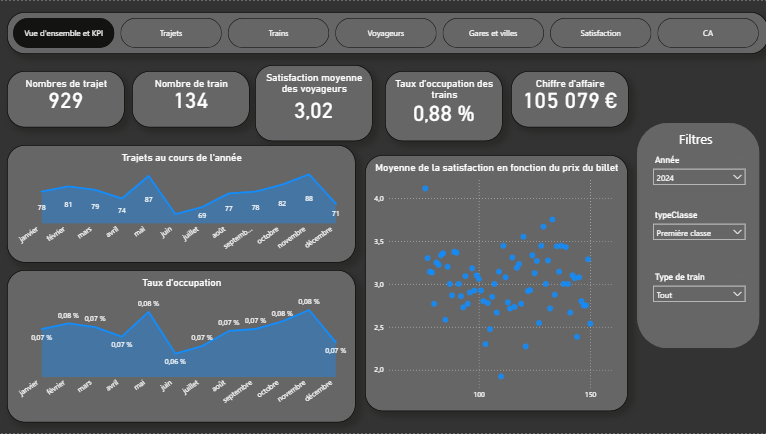
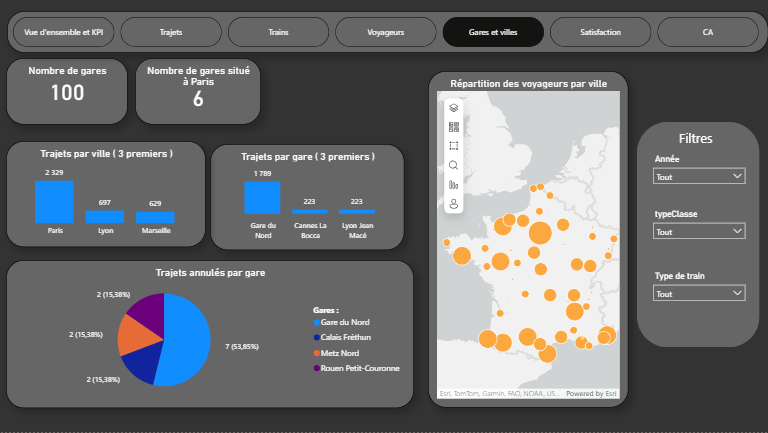
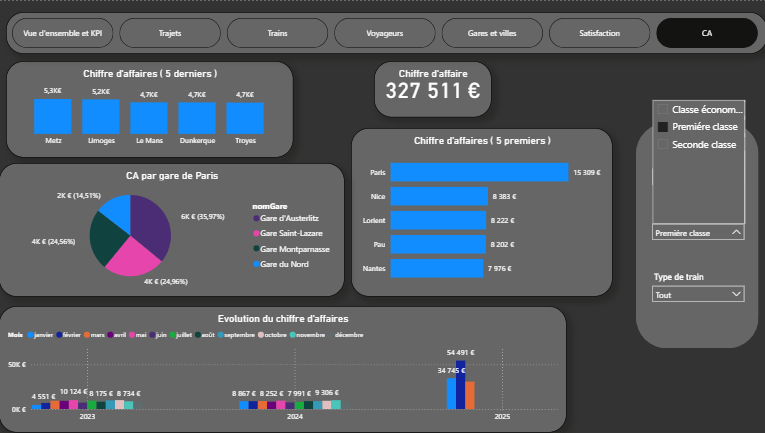
Apport analytique
Les tableaux de bord offrent une vision synthétique et exploitable des données, permettant d'identifier rapidement des tendances, des anomalies et des axes d'analyse pertinents. La visualisation n'est pas cosmétique : elle structure la réflexion.